Analisis dan Visualisasi Kecocokan Distribusi
analisis_distribusi.RdFungsi ini menganalisis sebuah set data untuk menentukan apakah distribusi Normal atau Eksponensial lebih cocok. Penentuan ini didasarkan pada Akaike's Information Criterion (AIC). Fungsi ini juga menghasilkan plot visual berupa histogram dengan kurva densitas dari kedua distribusi.
analisis_distribusi(x, na.rm = TRUE)Arguments
Value
Sebuah `list` yang berisi hasil analisis:
`hasil_normal`: List berisi `estimators`, `log_likelihood`, dan `AIC` untuk model Normal.
`hasil_eksponensial`: List berisi `estimators`, `log_likelihood`, dan `AIC` untuk model Eksponensial. (Akan bernilai NA jika data mengandung nilai negatif).
`rekomendasi_model`: String karakter yang menyatakan model terbaik berdasarkan AIC.
Fungsi ini juga akan menghasilkan sebuah plot pada *graphics device* aktif.
Details
Proses yang dilakukan fungsi ini adalah: 1. Menghitung MLE untuk parameter kedua distribusi menggunakan fungsi `mle_normal()` dan `mle_exp()`. 2. Menghitung nilai *log-likelihood* (\(\ell\)) untuk setiap model. 3. Menghitung AIC untuk setiap model dengan formula: \(AIC = 2k - 2\ell\), di mana \(k\) adalah jumlah parameter model (2 untuk Normal, 1 untuk Eksponensial). 4. Model dengan nilai AIC yang **lebih rendah** dianggap lebih cocok. 5. Membuat histogram data dan menempatkan kurva densitas dari kedua model di atasnya untuk perbandingan visual.
Examples
# Contoh 1: Data yang lebih cocok dengan distribusi Normal
set.seed(1)
data_norm <- rnorm(200, mean = 10, sd = 2)
hasil_analisis_1 <- analisis_distribusi(data_norm)
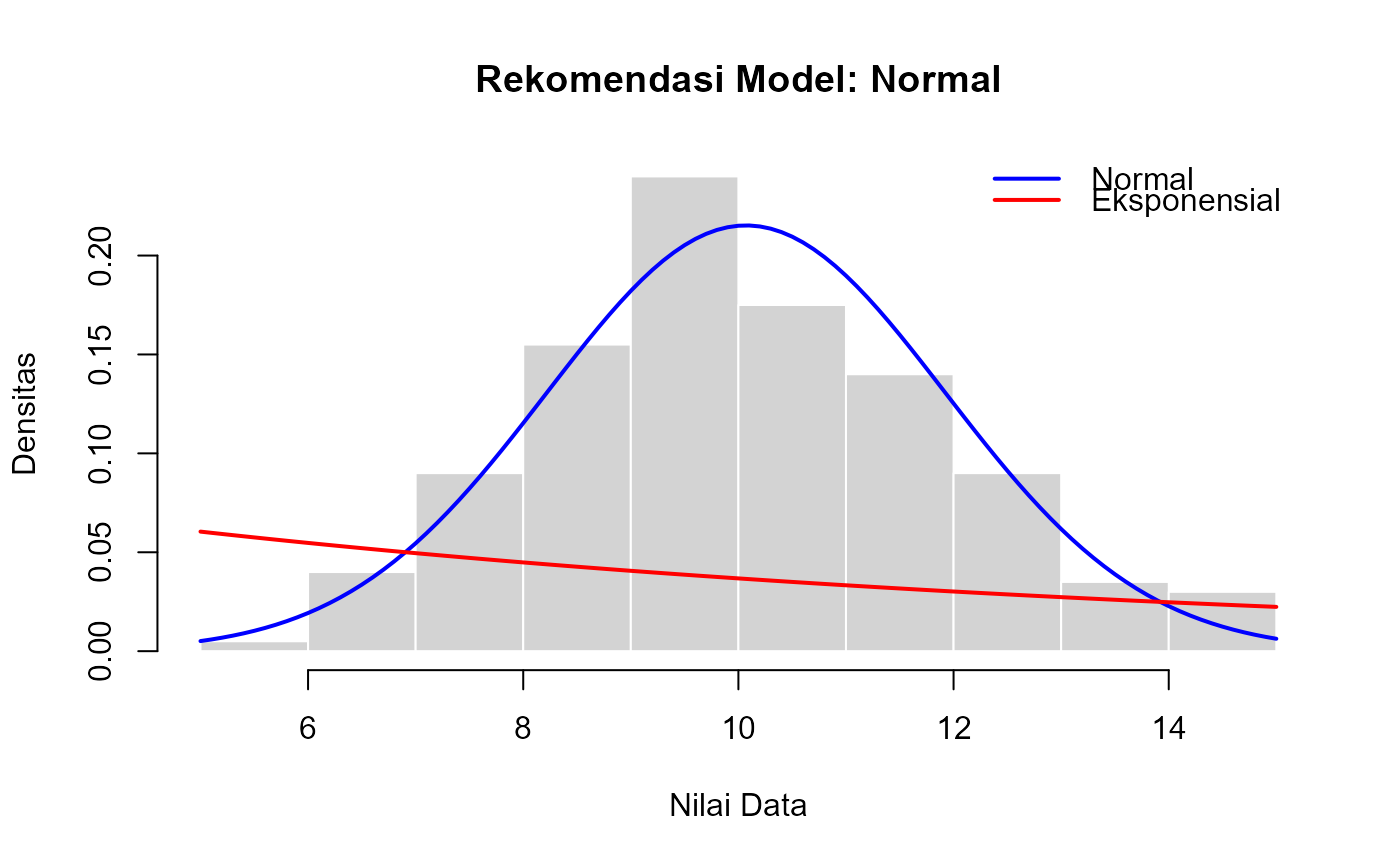 print(hasil_analisis_1$rekomendasi_model)
#> [1] "Normal"
# Contoh 2: Data yang lebih cocok dengan distribusi Eksponensial
set.seed(2)
data_exp <- rexp(200, rate = 0.5)
hasil_analisis_2 <- analisis_distribusi(data_exp)
print(hasil_analisis_1$rekomendasi_model)
#> [1] "Normal"
# Contoh 2: Data yang lebih cocok dengan distribusi Eksponensial
set.seed(2)
data_exp <- rexp(200, rate = 0.5)
hasil_analisis_2 <- analisis_distribusi(data_exp)
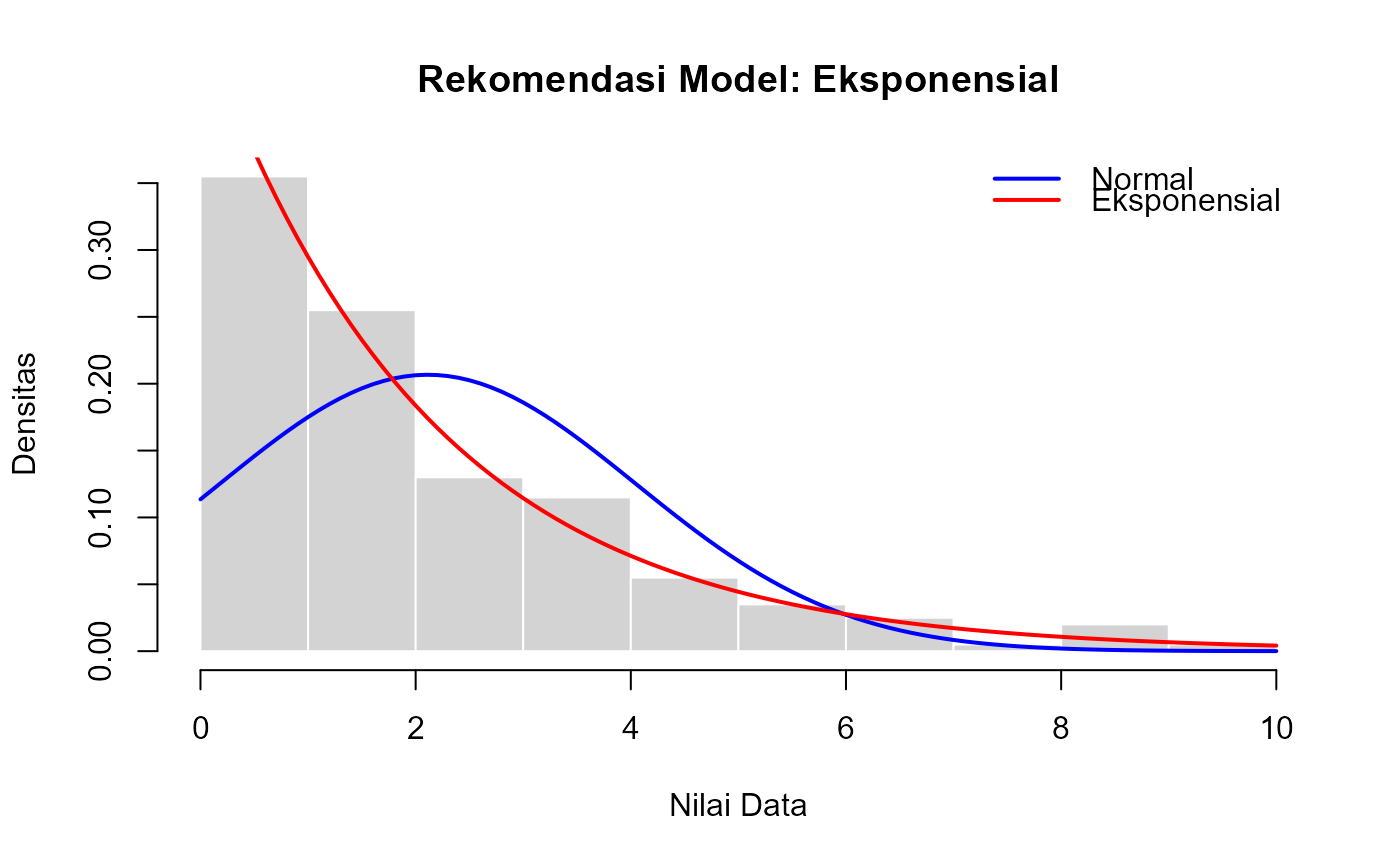 print(hasil_analisis_2$rekomendasi_model)
#> [1] "Eksponensial"
print(hasil_analisis_2$rekomendasi_model)
#> [1] "Eksponensial"